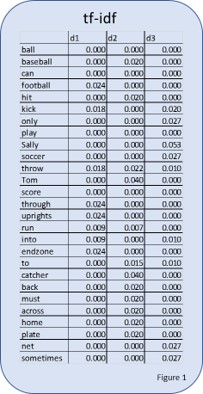
First, you will notice that tf-idf takes the three documents and converts them into a long skinny list. This list can be thought of as a vector, the start being the top and the bottom being the end.
Yes, for the purpose of this simple example, our documents are just a few sentences each, but with this method the length of the document is irrelevant because the way we are going to quantify the visualization is to measure the angle from one line on the graph to another. (You can imagine if we computed a tf-idf vector for a book or long article that a wide and very long structure of words would become a shorter vector).
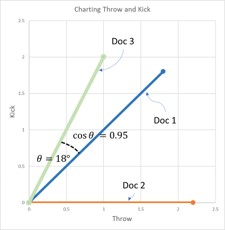
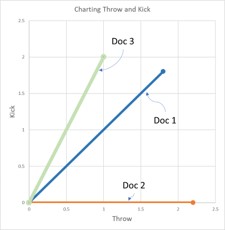
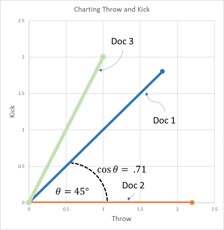
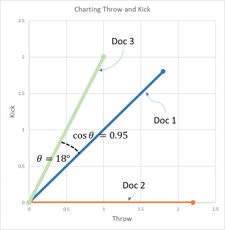
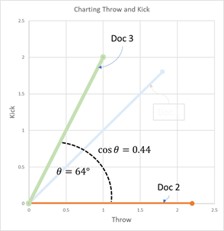
Basically, we are using the tf-idf data to determine a similarity score, which is the cosine (the angle) that exists between the tf-idf vectors (or lines on the graph) of two documents. The documents with the smallest angle between them on the graph feature more similarities than differences.
Once we have the vectors, we plot them on our graph. Each word would be an axis in the graph and you would have a line for each document. However, even for our very simple example we would require a 12-dimensional graph. While computers can plot information like this, it’s impossible to demonstrate in 2D.
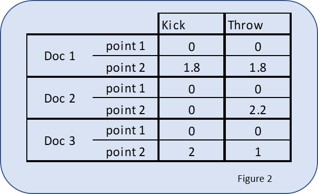
To create a 2D graph we will simplify our example. Let’s assume for the purpose of this article that you are only interested in the words ‘throw’ and ‘kick.’ Perhaps you are trying to invent a game where you throw or kick a ball, and want to make sure no one else has done this before. By simplifying it to only two terms, this allows us to create a 2-dimensional graph with ‘throw’ on one axis and ‘kick’ on the other.